Speech-to-3D
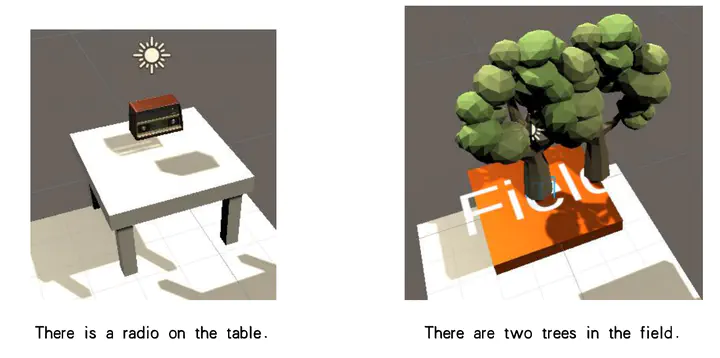
With deep learning playing an increasing role in people’s lives and the widespread dissemination of the concept of metaverse, many deep learning tools are being used to create metaverse scenarios. However, speech as the most common way of communication between people has rarely been studied for generating 3D unreal scenes. In this work, we addresse the problem of speech-based scene generation in current related research and proposes Speech-to-3D (S3D), a speech-based 3D scene generation tool that contains positional relations. In a pipelined mode, speech is converted into text, then entity recognition and strict location relationship judgement are performed to generate scene building instructions, and the instructions obtained from the analysis are fed into a third-party scene generation tool to generate 3D scenes. Speech recognition, keyword extraction, preposition analysis and Unity game engine technologies were used to generate high quality 3D scenes through speech and to accurately locate the positional relationships between components in the language description. Experimental results show that S3D outperforms existing work in terms of generation efficiency and generation quality.
Dingjie Song
Graduate student in Nanjing University
My research interests include natural language processing and deep learning.